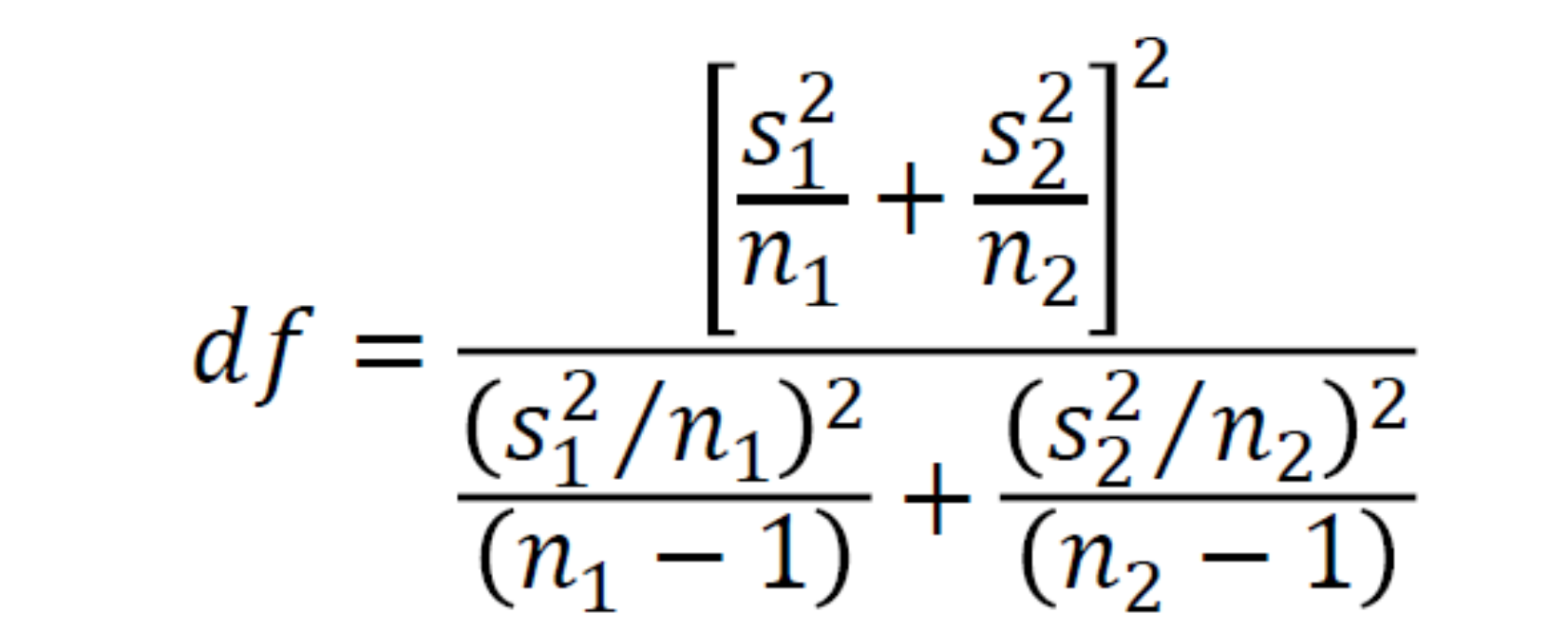Connecting Packaged R Code with Concepts + Intro to regression
Lecture: Not Sure
Dr. Elijah Meyer
NC State University ST 511 - Fall 2024
2024-10-30
Download today’s AE oct-30 from Moodle. We are going to learn a new distribution!
…not really, but you still need to download the AE for today
Checklist
– Keep up with Slack
– Upload today’s AE. We will be using this to start class
– Homework 3 (including exam corrections) due Sunday (11:59pm)
– Quiz Wednesday (due Sunday)
– Statistics experience (released; due end of semester on Gradescope)
– Optional assignment (released; due November 1st on Gradescope)
Learning objectives
– Review some common “pre-packaged” functions you will commonly see used to analyze data
– Understand what the output means / describe the output
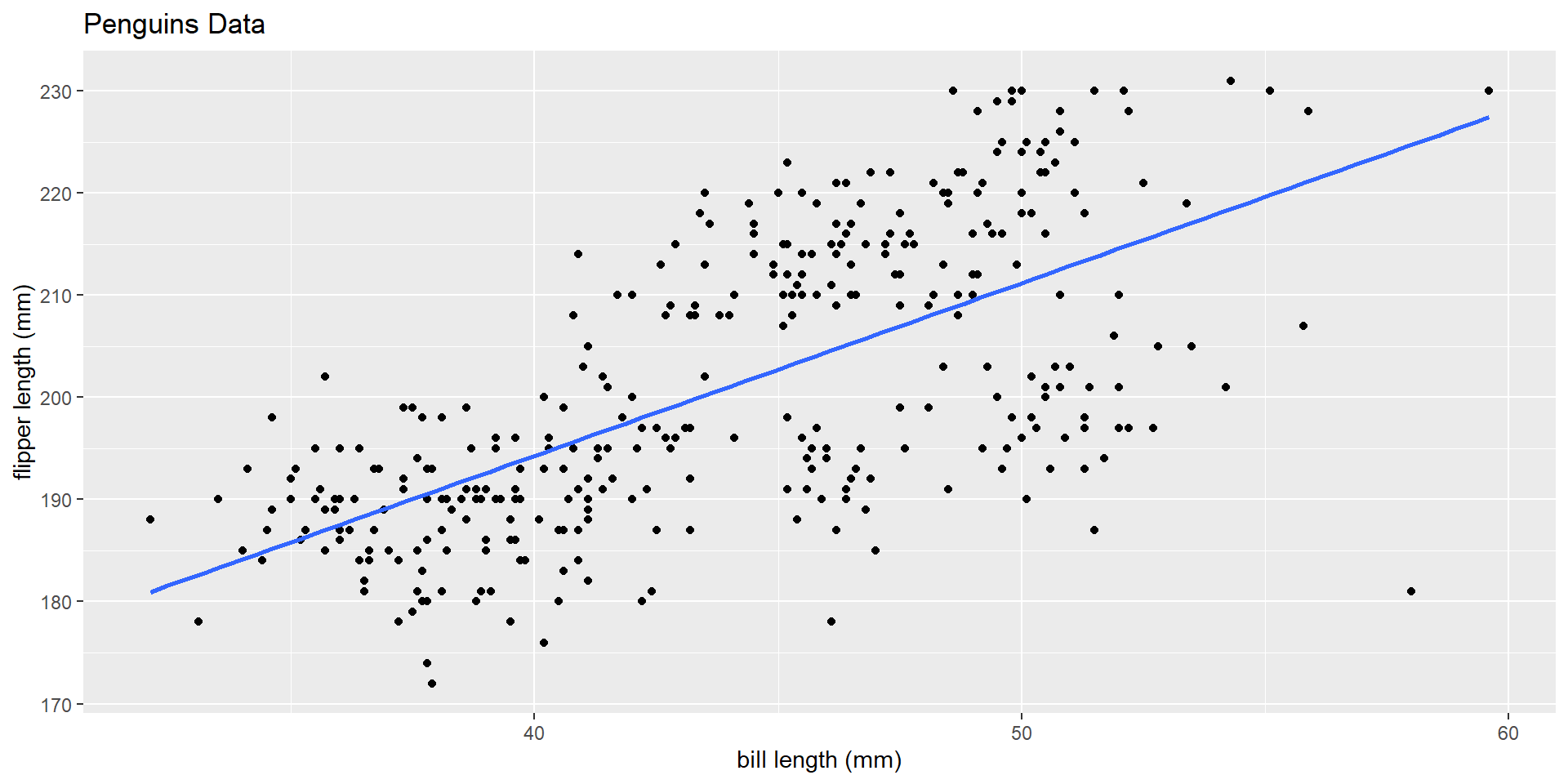
– What is regression?
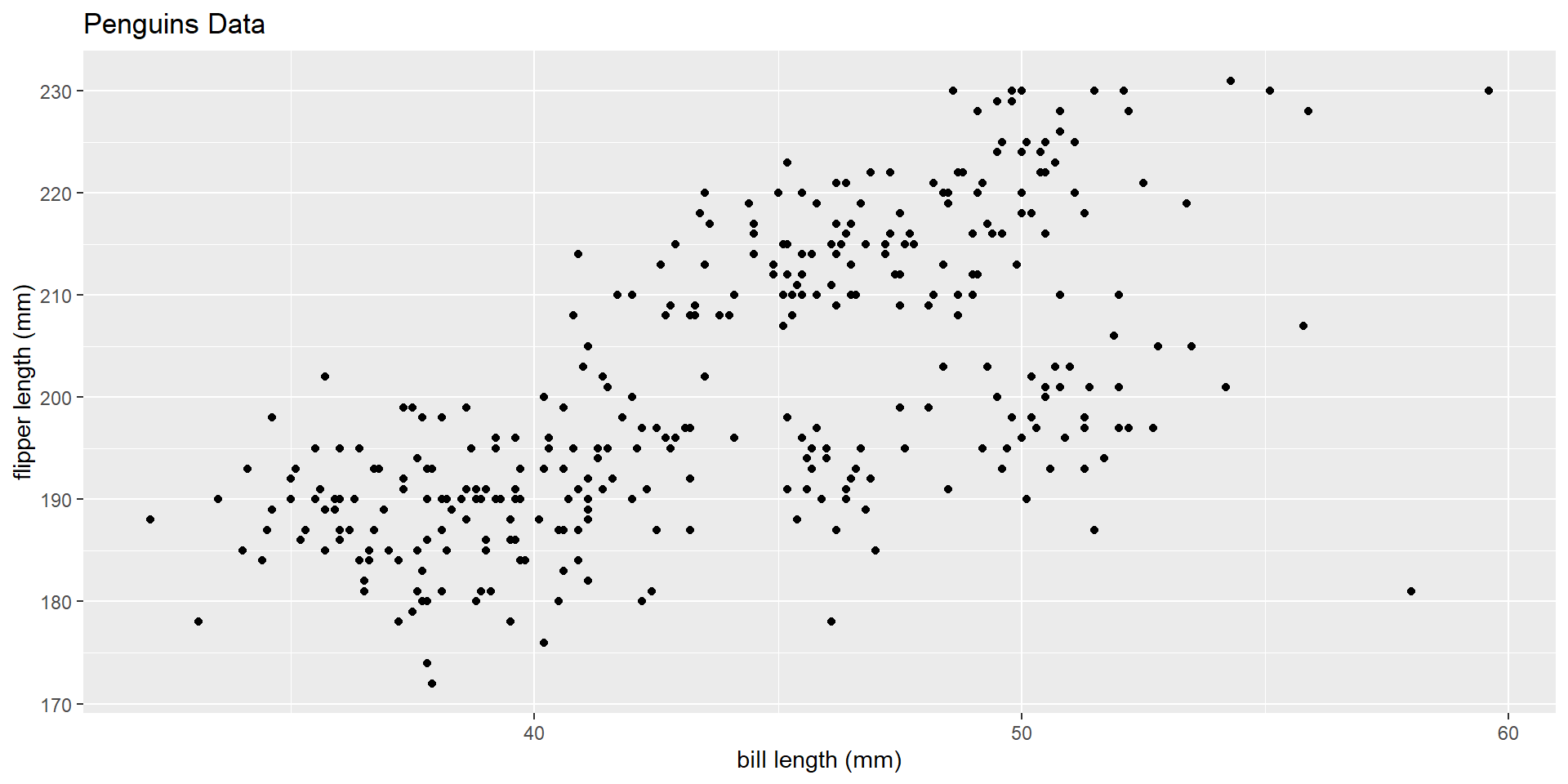
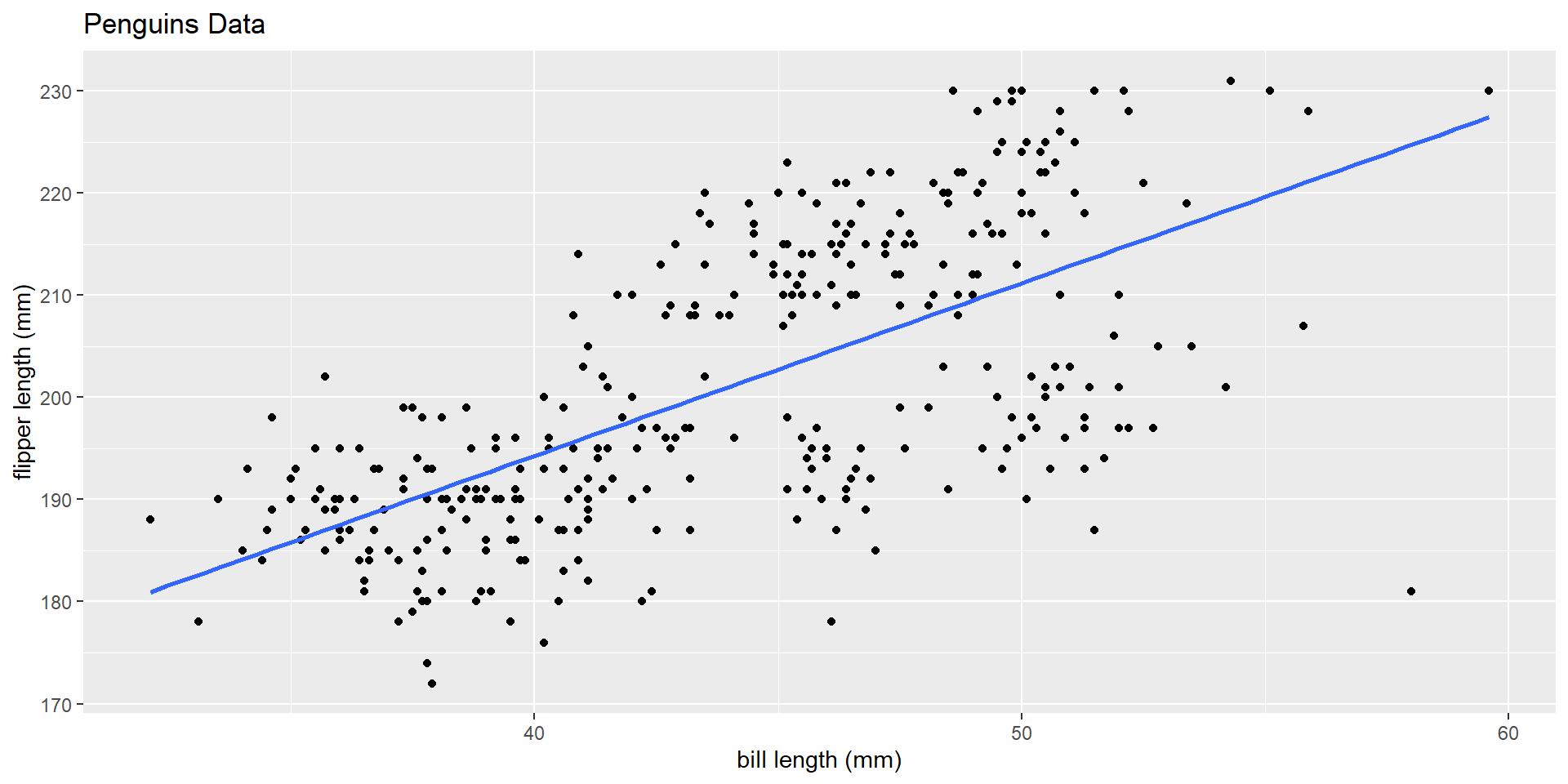
– Understand how to summarize two quantitative variables
The AE
Before we get into the AE, I want to make it clear that this AE is designed for us to explore and understand common data analysis functions in R, and make connections to what we’ve learned in class.
A rigorous analysis would include:
– Exploratory data analysis
– Checking assumptions
– Writing decisions + conclusions
– ect.
I want you all to be familiar with these functions in R, just in case you come across/need them in your future work.
– Note: We can also check for constant variance. If we find this to be true, we can use a different type of SE.
t-test
One-sided confidence interval
You do not need to know this for this course.
“In a one-sided confidence interval, we’re trying to find a single number a such that we’re 95% confident that the true mean is greater than a (or less than a if you set one.sided=”less”)“.