– Statistics experience (released; due end of semester on Gradescope)
– Optional assignment (released; due November 1st on Gradescope)
Announcement
Statistics experience found at the bottom of our website
– Attend a talk or conference
– Talk with a statistician about their work
– Listen to a podcast / watch a video
– Read a book
Make one slide summarizing your experience. Submit the slide as a PDF on Gradescope.
– Name and brief description of the event/podcast/competition/etc.
– Something you found new, interesting, or unexpected
– How the event/podcast/competition/etc. connects to something we’ve done in class.
– Citation or link to web page for event/competition/etc.
– Something else (ask me if it fits the goal of this assignment)
Announcement
Optional assignment
– Write a short paragraph on what you found interesting about the posted article on our website
– Starter qmd found on Moodle
– Turn in on Gradescope
Exam-1 in-class
– Grades are posted
– Solutions are posted (don’t share them please…)
– The exam regrade can be found at the end of Homework-3 (adds 6 points/7% to your in-class score)
– Please visit office/ see slides/ send emails about the content
Questions
Learning objectives
– Understand Anova output
– Understand why we use Tukey’s HSD
– Understand Tukey’s output
Last time
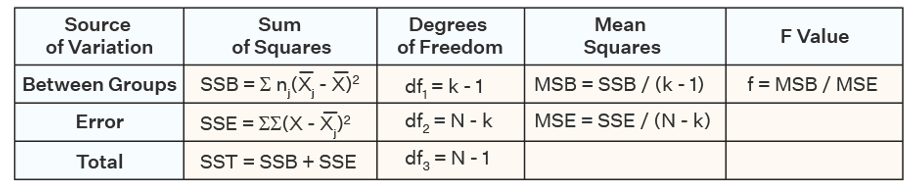
# Compute the analysis of varianceres.aov <-aov(bill_length_mm ~ species, data = penguins)# Summary of the analysissummary(res.aov)
Df Sum Sq Mean Sq F value Pr(>F)
species 2 7194 3597 410.6 <2e-16 ***
Residuals 339 2970 9
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
2 observations deleted due to missingness
Where did these numbers come from? What are the ideas behind these numbers?
The numbers
The numbers
Sums of squares (between) - how spread out the sample means are from the overall between (between group variation)
Sums of squares (error) - how spread out observations are from their group mean (within group variation)
df - number of groups - 1 & total sample size - number of groups
MSB - “average” sum of squares for the factor and error term
f = the ratio of the mean squares
What does this tell us?
p-value < 0.001
\(H_o: \mu_g = \mu_c = \mu_a = 0\)
\(H_a: \text{at least one population mean bill length is different}\)
Which one(s)?
Which means are different
Why can’t we just do a bunch of difference in means test?
Type 1 error
\(\alpha\) is our significance level. It’s also our Type 1 error rate.
a Type 1 error is:
– rejecting the null hypothesis
– when the null hypothesis is actually true
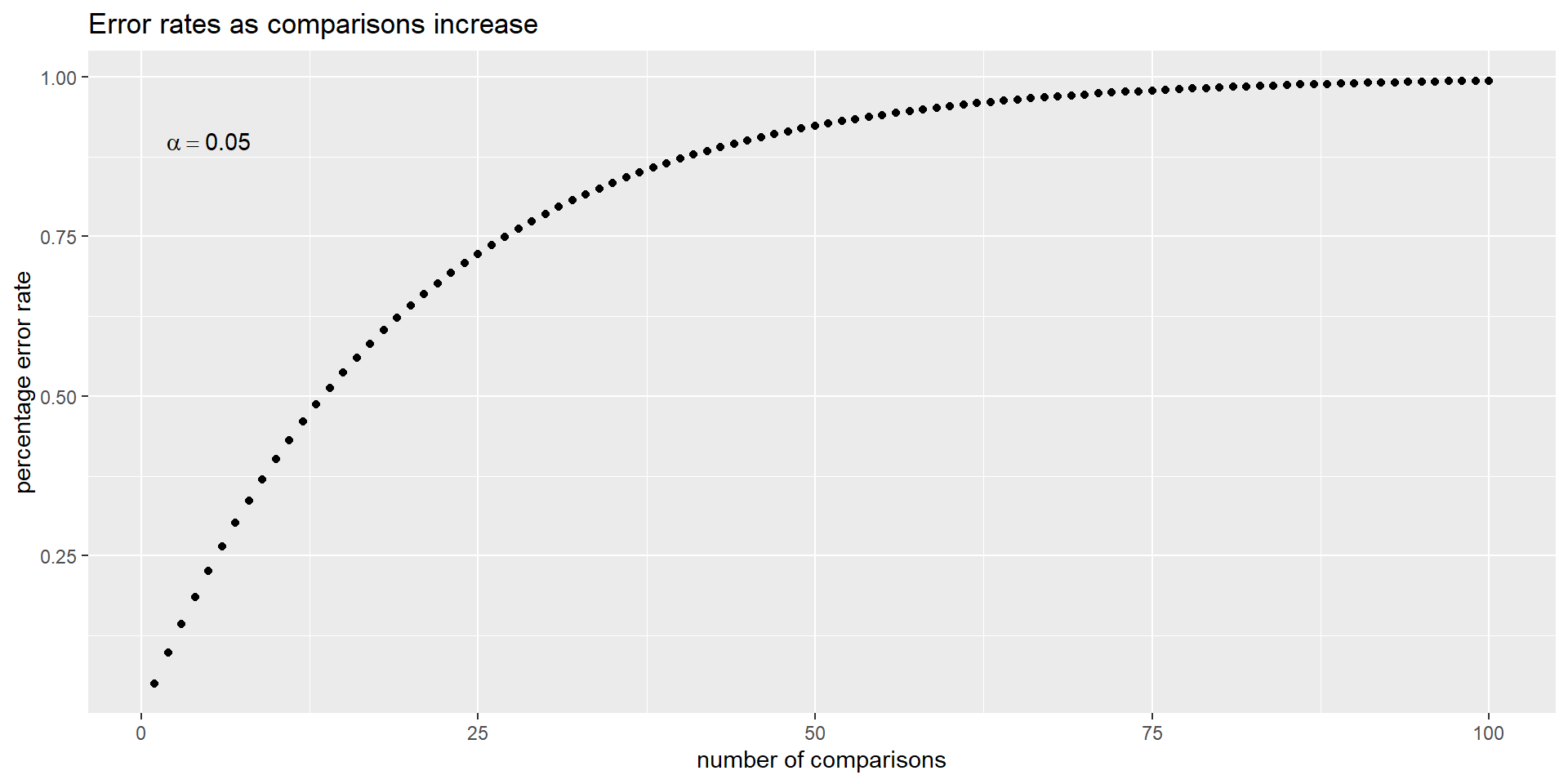
Family-wise error rate
FWER = \(1 - (1-\alpha)^m\)
where m is the number of comparisons
We are going to use \(\alpha\) = 0.05 for this our example
Plot
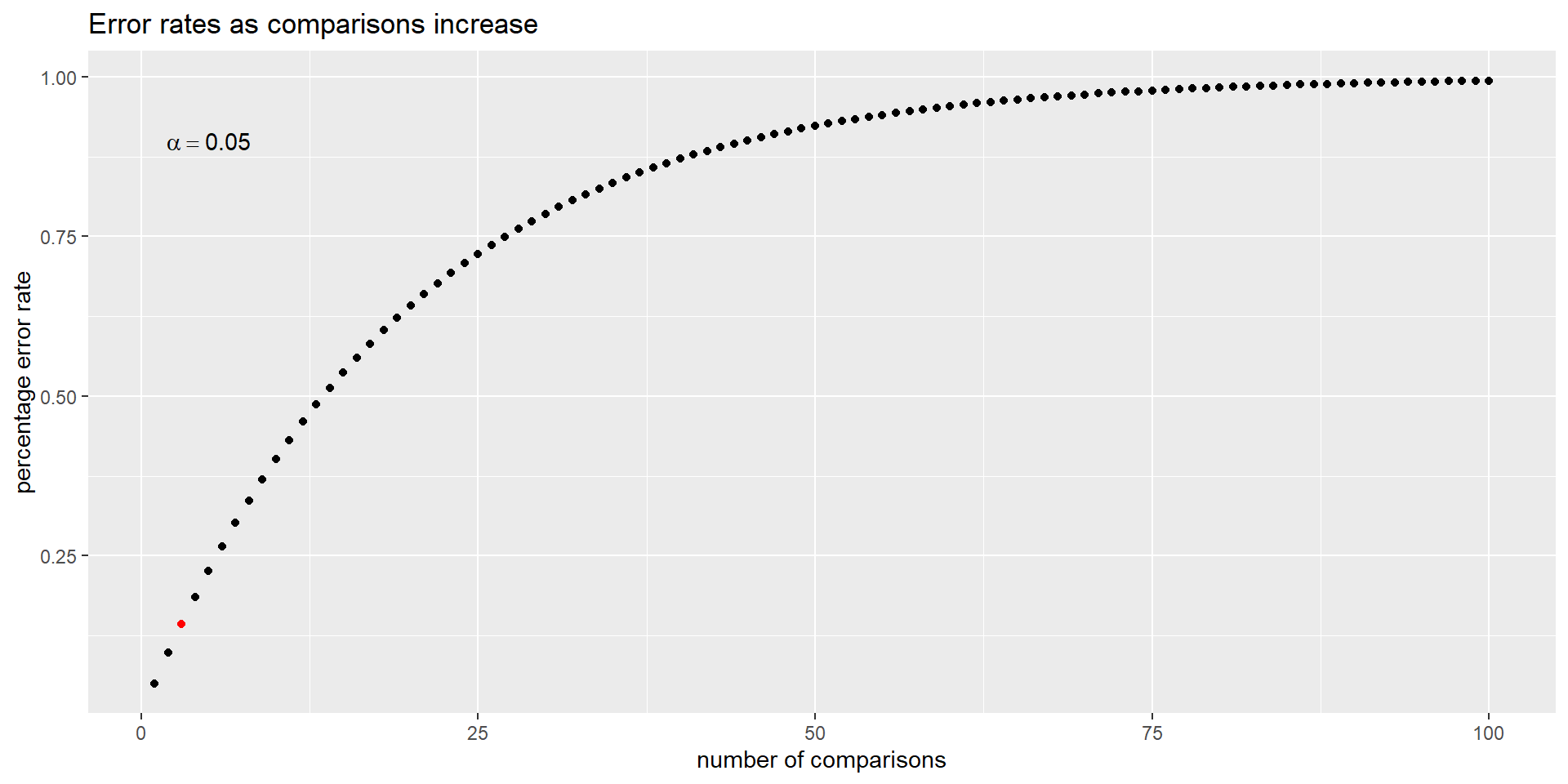
Family-wise error rate
How many comparisons do we have across our 3 species?
Family-wise error rate
m = 3
FWER = \(1 - (1-.05)^3 = 0.143\)
Questions on why we can’t just do a bunch of individual t-tests?
So how do we fix it?
Tukeys HSD
The main idea of the hsd is to compute the honestly significant difference (hsd) between all pairwise comparisons, controlling for the increase in error rate.
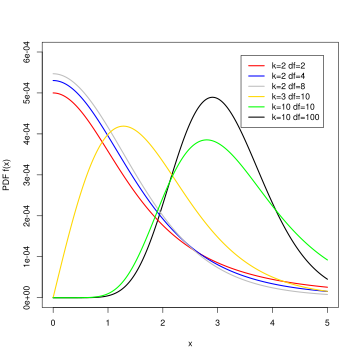
where q follows a studentized range distribution. This is a right tailed distribution (similar to an f-distribution). This is why we take the absolute value of our statistic.
Studentized range distribution
Note
This is almost identical to a t-test that we’ve done before.
We are accounting for the inflated type-1 error rate by using a new distribution (studentized range distribution) to conduct hypothesis tests and create confidence intervals.
Tukey results
peng_tukey <-TukeyHSD(res.aov)peng_tukey
Tukey results
Let’s walk through the third comparison to really understand where this output comes from (Gentoo-Chinstrap)
Info
# A tibble: 3 × 3
species mean count
<fct> <dbl> <int>
1 Adelie 38.8 151
2 Chinstrap 48.8 68
3 Gentoo 47.5 123
q
Note: R rounded our MSE to 9 from 8.76. I’m using 8.76 to be more exact.
We need to find the correct q* value that excludes 5% on the right tail to calculate our 95% confidence interval (because the studentized range distribution is right tailed).
syntax: ptukey(quantile, number of groups, residual (error) df)
The results from the Anova was to conclude that at least one true mean bill length was different. What do the following results tell us below?
AE
Summary
Tukey’s Honest Significant Difference (HSD) test is a post hoc test commonly used to assess the significance of differences between pairs of group means. Tukey HSD is often a follow up to one-way ANOVA, when the F-test has revealed the existence of a significant difference between some of the tested groups.