By submitting this exam, I hereby state that I have not communicated with or gained information in any way from my classmates during this exam, and that all work is my own.
Any potential violation of the NC State policy on academic integrity will be reported to the Office of Student Conduct & Community Standards. All work on this exam must be your own.
This exam is due Tuesday, October 15th, at 11:59PM. Late work is not accepted for the take-home.
You are allowed to ask content clarification questions via Slack. Any question(s) that give you an advantage to answering a question will not be answered.
This is an individual exam. You may not use your classmates or AI to help you answer the following questions. You may use all other class resources.
Show your work. This includes any and all code used to answer each question. Partial credit can not be earned without any work shown.
Round all answers to 3 digits (ex. 2.34245 = 2.342)
Only use the functions we have learned in class unless the question otherwise specifies. If you have a question about if a function is allowed, please send me an email.
If you are having trouble recreating a plot exactly, you still may earn partial credit if you recreate the plot partially.
Do not forget to render after each question! You do not want to have rendering issues close to the due date.
Reminder: Unless you are recreating a plot exactly, all plots should have appropriate labels and not have any redundant information.
Reminder: The phrase “In a single pipeline” means not stopping / having no breaks in your code. An example of a single pipeline is:
Hide the warning text (not the code itself) using the appropriate code chunk argument for the packages code chunk. You do not need to include any text to answer this question (just hide all the extra text). Hint: You can find a list of these arguments here in the Options available for customizing output include: towards the top.
We are going to use the very familiar penguin data for question 2.
In a single pipeline, calculate the median bill length for each species of penguin. Your answer should be a 3x2 tibble.
In a single pipeline, calculate the min, max, and IQR of bill length for each species of penguin. Your answer should be a 3x4 table. Hint: Check the help file for the function summarize() for Useful functions.
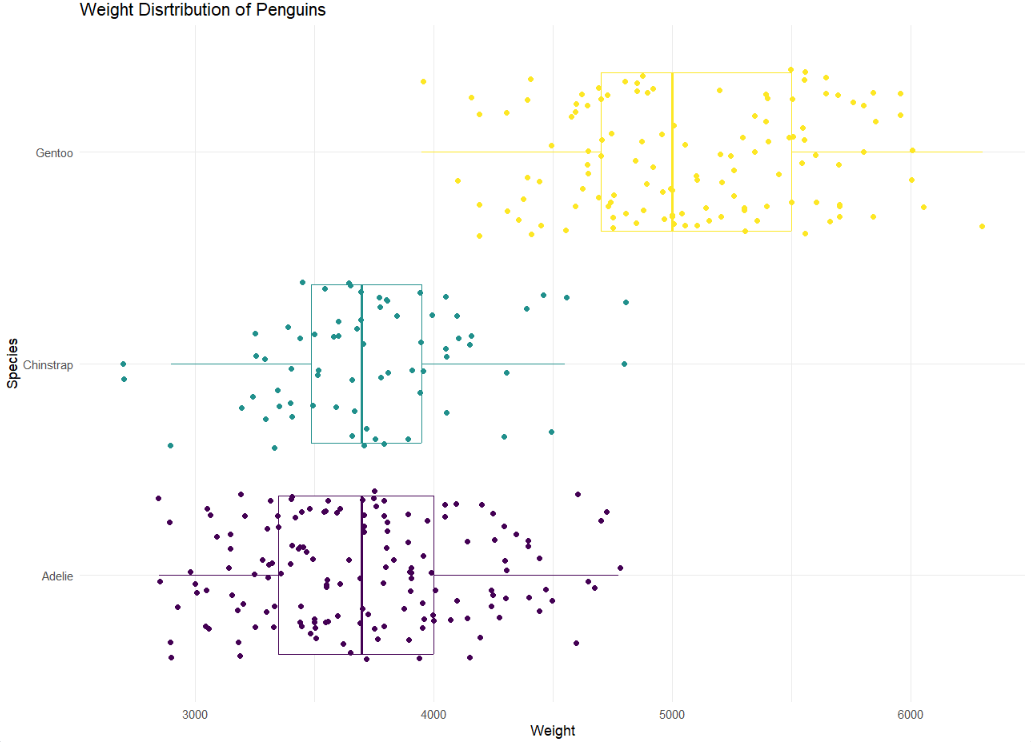
In a single pipeline, recreate the following plot below.
Hint: This plot uses theme_minimal and scale_color_viridis_d(option = “D”)
Note: Your dots will not look exactly the same as the graph below. They will be similar.
Now is a good time to save and render
Question 3: Flights simulation
Data
Read in the airplanes_data.csv for the follow questions.
creating a confidence interval for estimating the difference between the average flight distance for the different types of customers.
Be as precise and add context when possible, and use information from the actual data (e.g. sample sizes, etc.) in your answer. Use the order of subtraction loyal - disloyal
Now is a good time to save and render
Question 4: Flights confidence interval
In this question, you are going to create a simulation based 90% confidence interval for the scenario described in question 3. Do you expect the sampling distribution of your difference in means to be roughly normal? Justify your answer. Add to the existing code to create any appropriate plots that would help you justify your claim. You can make more than one plot for each group if you would like (start a new pipe the same way you see below). For this question, you can assume that one person’s flight experience is independent from another, regardless of group.
Pipeline with only loyal customer group
airplanes |>filter(customer_type =="loyal_customer") |># insert code here
Pipeline with only disloyal customer group
airplanes |>filter(customer_type =="disloyal_customer") |># insert code here
Regardless of your answer above, Add to the existing code below by replacing the ... with the appropriate information to create your simulated sampling distribution, as described in question 2. You are saving your simulated difference in means into a data set called boot_df
Fill in the … for set.seed with your NC State ID number (ex. 001138280). Report a glimpse() of your new boot_df to answer this question.
set.seed(...)boot_df<-airplanes|>specify(response =..., explanatory =...)|>generate(reps =1000, type ="bootstrap")|>calculate(stat ="...", order =c("loyal_customer", "disloyal_customer"))
Plot a histogram of boot_df. Where is this distribution centered? Why does this make sense?
Now, create a 90% confidence interval using your boot_df data frame by filling in the ... below. Then, interpret this interval in the context of the problem.
Discuss one benefit and disadvantage of making an 80% confidence interval instead of a 90% confidence interval.
Now is a good time to save and render
Question 5: Testing flights
In this question, we are tasked to conduct a theory based hypothesis test to see if there is a relationship between a customer’s type of travel, and their overall satisfaction of the flight. That is, does the type of travel impact their satisfaction? We are investigating if customers who are traveling for personal travel are satisfied more often then those those who are traveling for business travel.
For this question, we are going to use the following variables.
satisfaction - was the customer satisfied or dissatisfied with their experience
type_of_travel - was the travel for business or personal
Below, carry out the necessary steps to conduct a theory based hypothesis test (z-test). Show all your work. You may assume \(\alpha\) = 0.05. At the end of your hypothesis test, write your decision and conclusion in the context of the problem.
\(H_o\):
\(H_a\):
Question 6: ChickWeights
For this question, we are going to use a chickweight data set. This is a data set that has data from an experiment of the effect of diet on early growth of baby chickens. Please read in the following data below.
Data
The data key can be seen below:
variable name
description
time
The week in which the measurement was taken (0, 2, 4, 6, 8).
chick
ID number (1, 2, 21, 22)
diet
type of diet(1, 2)
weight
body weight of the chick (gm)
The data can be read in below. Note that we can use as.factor() to make sure R is treating a variable as a category.|
Rows: 20 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (4): time, chick, diet, weight
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Report the mean and standard deviation for weight for each measurement day. This should be a 5 x 3 tibble. Name the columns mean_weight and spread.
As researchers, it’s critical that you demonstrate your ability to learn and implement new computing skills. In the next two questions, you are going to demonstrate your ability to build upon your existing computing R/statistics skills.
The chicken weights are measured in grams. Suppose that, instead of grams, you want to have the weight measured in ounces. We are going to learn a new function that allows us to create new variables. This function is called mutate(). The help file for mutate() can be found here. mutate() is in the dplyr family, and has similar arguments to functions we have used commonly in class, such as summarize(name = action).
One gram is 0.035274 ounces. In one pipeline, create a new variable called mean_weight_o or weight_o (which is more appropriate) that represents the number of ounces a chicken weighs and calculate the mean weight and standard deviation of your new mean_weight_o/weight_o variable for each combination of time and diet. This should be a 10 x 4 tibble.
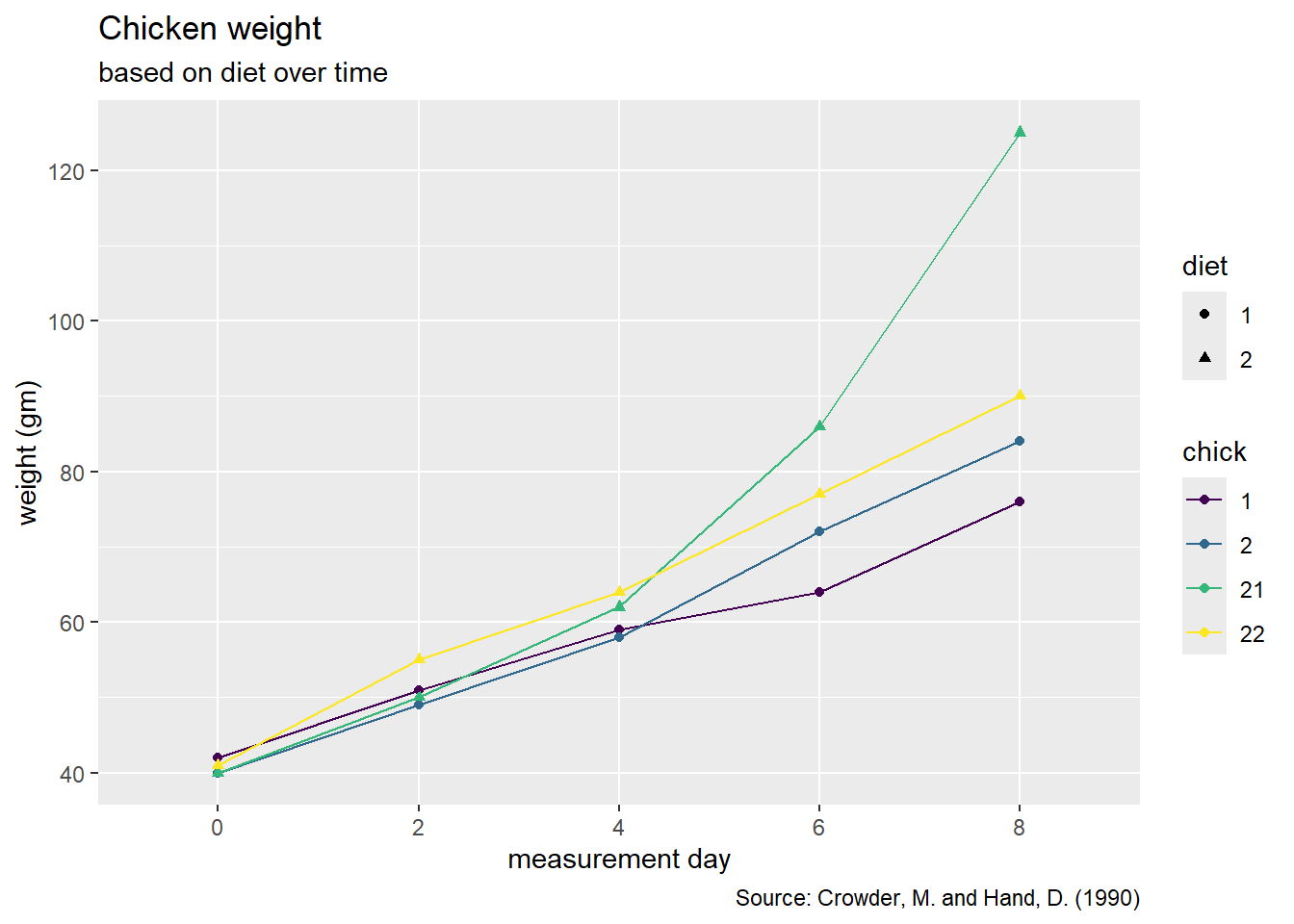
Please recreate the following graph below.
As a reminder, a list of geoms in the tidyverse package can be found here.
Hint: Go to the reference above and look for the geom that connects observations with a line.
Hint: To recreate this plot, we need to specify a group = variable.name to tell R which observations we want to connect to each other in the aes() function.